A powerful feature in the Speech Tuner is the ability to organize and analyze your data by menu. A menu is a group of one or more grammars that are used together, and should correspond roughly to a single dialog state within a speech application. A menu might correspond to a single grammar, such as a yes/no grammar or a simple commands grammar, or it might be a combination of grammars (like a commands grammar and a universal help grammar).

Across the top of the Tuner, just underneath the main toolbar, you can see the Menu: selector. By clicking the drop-down, you can focus on a particular menu.
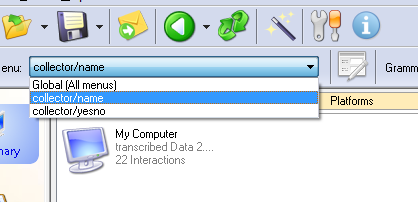
By picking a specific menu, the Tuner will apply a filter so that only data from the selected menu is shown. This means if you want to just transcribe data from a single menu, you can select that menu and go the Transcriber. This holds true for other parts of the Tuner, including the Tester and its statistics. The Tuning Wizard also allows you to look only at specific menus when running analyses.
The Global (All menus) menu is always selected by default, which shows all data across all menus.
Menus are further divided into grammar sets. A grammar set is a unique copy of the grammars used in a menu. For example, let's say you had a menu that consisted of a names grammar for an auto-attendant that you deployed on Monday. Then on Tuesday, you update the grammar to add an entry when a new person joins the company. On Wednesday, you remove an entry after an employee retires. There is still just a single menu, but there exist three unique copies of the grammar. Each of those different copies represents a unique grammar set within the menu.
Note that this holds true even when you have multiple copies of a grammar. If your names menu also used a global help grammar that did not change, you'd have three distinct grammar sets: all three would have the unchanged help grammar, but the names grammar would be different in each grammar set. Unless you are tuning an application that has a lot of changes or dynamic grammars, you will probably find yourself focusing on menus more than on grammar sets. Many applications will only have a single grammar set per menu, but it's good to be aware of the distinction for the times when it comes up.
Determining Which Menus Exist
By default, the Speech Tuner assumes that any grammars with the same URI are the same grammar for purposes of determining a menu. So if an ASR interaction loaded grammars from http://grammar-server/names.grxml and http://grammar-server/help.grxml at the same time, the Tuner would assume that was a single menu. If another interaction used grammars from builtin:grammar/Boolean and http://grammar-server/help.grxml, the Tuner would assume that was a separate menu.
One exception to this is grammars which are loaded as buffer grammars. This may happen with API users who call LoadGrammarFromBuffer or for MRCP/VXML users who load grammars inline. In that case, the ASR has no URI for the grammar, so instead the Tuner looks at the root rule's name in place of the URI.
This method of calculating menus is useful because it means that even if a grammar at a specific URI changes, that change will be noted as two grammar sets within the same menu. For some uses cases, however, there the URI method does not work well. For instance, a URI could really be an application which generates drastically different dynamic grammars. In that case, you may wish to change how the Tuner calculates what constitutes a menu. This can be done in the Tuner's Advanced Settings window (from the toolbar pick Edit > Advanced Settings).
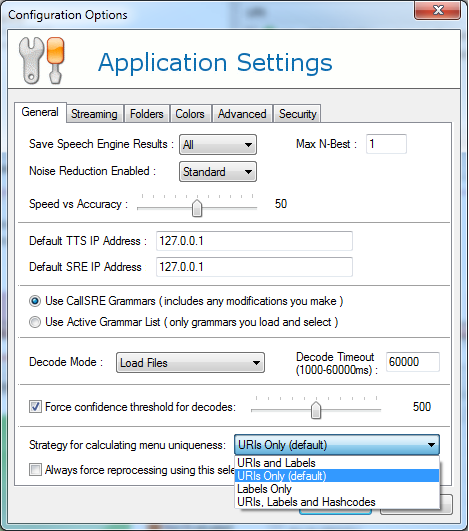
The Strategy for calculating menu uniqueness drop-down offers four options:
- URIs and Labels. This considers a grammar to be the same as another grammar if its URI and grammar label are the same. Grammar labels are set in LoadGrammar calls via our API. For MRCP/VXML users, the grammar label is the MRCP Content-ID for the grammar set in a DEFINE-GRAMMAR message. Because most MRCP/VXML voice platforms do not provide the user the ability to set Content-ID, this option is probably not a good choice for MRCP users. However, API users may find they get better behavior when using this option.
- URIs Only (default). This is the default behavior described above, where a grammar is considered the same as another if its URI is the same.
- Labels Only. In this case, URIs are ignored and only the label is used.
- URIs, Labels, and Hashcodes. This specifies that a grammar is only the same as another grammar when their URI, label, and a hash of their content is the same. Using this functionality essentially makes grammar sets useless, as two grammars that have the same URI/label but different content would normally be put in separate grammar sets. With this option selected, they would be in different menus and different grammar sets. This option would generally be selected only by users who are using very different dynamic grammars generated by the same URI.


