The Transcriber is used to enter transcripts for interactions. Transcripts are necessary for a number of advanced statistics and tests, as well as when using the Tuning Wizard.
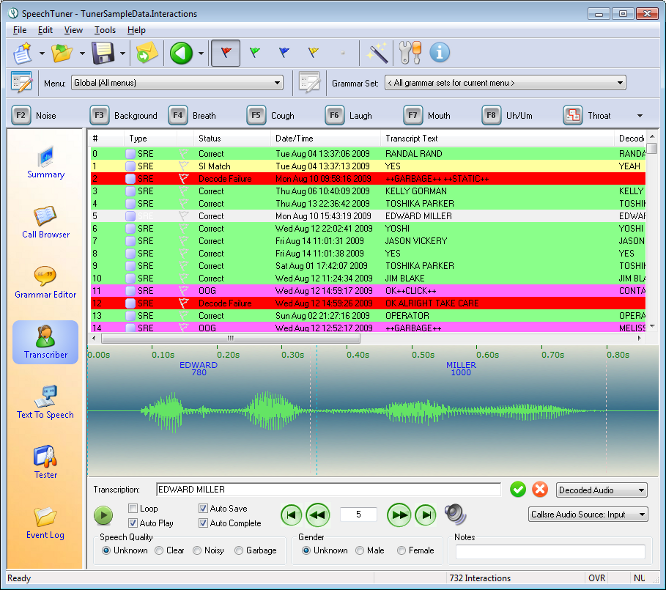
The top of the Transcriber contains a list of all loaded and filtered interactions. The same information is displayed in this area as the Call Browser's, or Tester View's interaction list.
The bottom portion of the screen contains audio and transcription controls. The Transcription text entry box allows you to type in a transcript of what the caller said. By default, this will be populated by what the ASR recognized. Default text from the ASR decode appears as red while text entered or approved by a transcriber appears as black.
In most cases, you can simply type the transcript and press the Enter key to move to the next interaction. You may also click the green check mark  next to the transcription entry box to achieve the same purpose.
next to the transcription entry box to achieve the same purpose.
Out-Of-Coverage
In some cases, it may not be possible to determine what a speaker said, due to line noise or other issues. We call this sort of audio Out-Of-Coverage (OOC) because it does not contain particularly useful data. You can press the Escape key to mark a piece of audio as OOC and move on to the next interaction, or you can press the red X symbol  . Note that interactions marked as OOC will not be used in accuracy statistics.
. Note that interactions marked as OOC will not be used in accuracy statistics.
Out-Of-Grammar
Certain phrases spoken by users are not catered for in the active grammar, and these will be automatically marked as Out-Of-Grammar (OOG) by the Speech Tuner. The Tuning Wizard can use this information to suggest whether certain OOG phrases should be added to the grammar coverage, thus changing their status from OOG.
For most transcription purposes, typing transcripts and marking bad audio as OOC is sufficient. This will let you generate most of the useful statistics you need for normal speech application tuning purposes.
However, you may need finer information about interactions, in which case advanced controls and noise tags are available.
Immediately below the transcription entry box are some audio controls. You can press the green play button  to play the audio. The Loop check-box will cause the Tuner to loop the audio for as long as the interaction is selected. The AutoSave check-box causes the Tuner to automatically save entered transcripts.
to play the audio. The Loop check-box will cause the Tuner to loop the audio for as long as the interaction is selected. The AutoSave check-box causes the Tuner to automatically save entered transcripts.
The Auto Play check-box causes it to automatically play the audio when an interaction is selected. The Auto Complete check-box causes the recognized text from the Engine to automatically populate the transcription text entry.
Next to the check-boxes are interaction controls that will allow you to return to the first interaction, go to the previous interaction, go to the next interaction, or jump to the last interaction. You may also manually type in an interaction index number to quickly jump to a specific interaction.
Noise Marker Toolbar
Along the top of the Transcriber View is a toolbar containing noise tags or markers. By default, these start with the general Noise marker and proceed to the right to show other markers. These buttons can be clicked to insert into the transcript special tags denoting general Noise, Background sounds,Breaths, Coughs, Laughs, miscellaneous Mouth noises, Uh or Um sounds,Throat clearings, Silence, or Garbage, along with other markers.
Function Keys F2 through F11 can also be assigned to these tags/markers allowing users a quick and convenient method of applying frequently used tags/markers by a single key press.
Starting with LumenVox version 13.0, users can configure this toolbar, and associated function keys as they wish using the Marker Toolbar Mapping dialog, which can be selected from the top menu, using Edit - Insert Marker String - Configure Toolbar option, or by selecting the Configure Toolbar option from the drop-down menu on the right-most button on the toolbar (the Quickmap Button).
These tags are rarely needed by application tuners and are primarily useful when transcribing audio for building new speech recognition acoustic models. If you are working with LumenVox on data collection for this purpose, we will provide you with detailed information about how to use these tags.
You may also mark the Speech Quality as Unknown,Clear, Noisy, or Garbage and you may indicate the speaker'sGender as Unknown, Male,or Female. Once again, these are mainly used for building acoustic models and are of little interest to most application tuners.
Finally, you may enter Notes about a particular interaction. Note that you can filter using text entered into this Notes area, which may be very useful.


