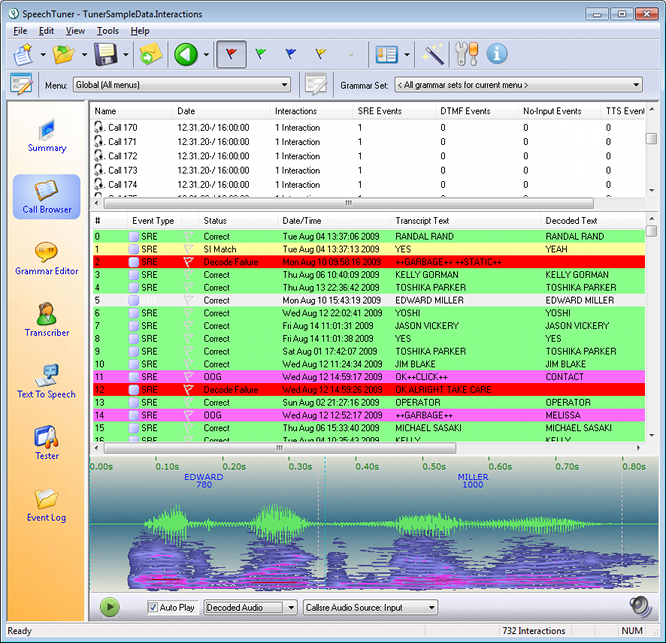
The Call Browser allows you to quickly navigate and listen to large numbers of calls and interactions.
The Tuner makes a distinction between a call and an interaction, and this is very apparent in the Call Browser. An interaction is a discrete Speech Engine event. The most common event type is a speech recognition event (abbreviated as SRE), but other events include DTMF, No Input, TTS, AMD and CPAevents.
A DTMF event is an interaction where DTMF (also known as Touch-Tone) was entered, and a No Input event is when the Speech Engine did not detect speech or DTMF.
A TTS event is the result of a TTS Speech Synthesis request (perhaps a prompt), which generally includes the phrase whose synthesis was requested.
AMD (Answering Machine Detection) and CPA (Call Progress Analysis) events are associated with the use of AMD and CPA functionality, which can also be analyzed using the Speech Tuner.
A call is a collection of individual events, and usually correlates to an entire telephone call. Depending on how you are saving your call files, however, you may only get one interaction per call.
Call List
The Call Browser is divided into three sections. The top section displays all the loaded calls. This is named the Call List.
Note: that the Call Browser is the one portion of the Tuner that does not obey filters - it will show all calls and interactions, even if the filters would otherwise exclude them.
The call list has two distinct views: a list view and a tiled view. To toggle between them, you can use the toggle view drop-down from the toolbar, or you can choose View > Show Calls as Tiles or Show Calls as List from the menu.
You can click on a call in the top section to see the corresponding interaction list for that call in the middle section. You may also select a group of calls to populate the interaction list with all the interactions for the selected calls.
Right-clicking on the Call List brings up context menu, which allows you to choose from the following options:
Keep Selection
Filters out all interactions that are not associated with the selected call(s).
Exclude Selection
Filters out all interactions that are associated with the selected call(s).
Save Data to File...
Allows you to save the list of calls to a file.
Properties
Displays advanced information about the selected call(s), including the number and types of events contained within them.
Interactions List
Each interaction for a call is displayed, and you can navigate through them. This is a good way to get a sense of how typical calls progress, from start to finish, and may allow you to pinpoint call flow issues that may not be apparent from just looking at individual interactions. The following information is displayed in the interaction list:
#
The index number for an interaction, this indicates the order of interactions within a call.
Event Type
The type of event (SRE, DTMF, No Input, TTS, AMD or CPA).
( flag )
Indicates whether the interaction has been flagged with one of the available color flags (useful for categorizing groups of interactions).
Status
Information about the status of the interaction. Possible status types are:
- Load Failure: the audio failed to load for some reason.
- Decode Failure: the decode failed.
- No Transcript: no transcript is available for this interaction.
- No Decode: the interaction was successfully loaded but no decode has been performed by the Speech Engine.
- No Transcript/Decode: no transcript is available for this interaction and there has not yet been a decode.
- Correct: the decoded text matches the transcript.
- SI Match: the decoded text differs from the transcript, but both have the same semantic interpretation.
- Incorrect: the Speech Engine returned a result that does not match the transcript (and the decoded text's semantic interpretation does not match the semantic interpretation of the transcript).
- OOV: the transcript's text is out of vocabulary, meaning the utterance is not a valid in-grammar sentence.
- Unprocessed: the Tuner has not yet processed this interaction.
- Inactive: This interaction has been filtered out.
Date/Time
The date and time for the interaction.
Transcript Text
If available, the transcript for the interaction.
Decoded Text
If available, what the Speech Engine recognized as the raw text for the interaction.
Transcript SI
The semantic interpretation for the transcript. This is calculated by parsing the transcript against the grammar for the interaction and using the semantic interpretation.
Decode SI
The semantic interpretation for the decoded text.
Conf
The confidence score for the interaction.
Error Type
Describes the type of error detected when a decode result is not correct. See the Utterance Accuracy Tuning article for more information about utterance errors.
Time
The amount of time, in milliseconds, it took the Speech Engine to decode the interaction.
You can also select which columns you wish to view by right-clicking on the header section of the Interactions list and selecting your preferred display options.
Audio Controls
Once you have selected an interaction, the bottom of the Call Browser displays the audio and audio controls for the Interaction. You can adjust the volume with the volume slider, click the check-box to Auto Play the audio upon selecting an interaction, and you can replay an audio file by clicking the green Play  button.
button.
A final important feature of the audio controls is the ability to toggle between three types of audio to listen to via the drop-down box. This is useful in debugging various issues related to audio. The three types are as follows:
Decoded Audio
The audio after LumenVox's processing. This is the audio that was ultimately used for the speech recognition event.
Streamed Audio
The entire audio stream that was sent to the Speech Engine, including any leading and trailing silence. This option is only available if advanced call logging is enabled. In the event of a No Input event, this will be the only audio available.
Loaded Audio
The raw audio as it was sent into the Speech Engine, before any LumenVox processing (e.g. noise reduction or volume normalization), but after silence has been trimmed.
Listening to the difference between streamed, actual, and decoded audio can be helpful in troubleshooting problems associated with audio quality.
For instance, the actual utterance may be extremely quiet, and aggressive volume normalization in the decoded utterance may cause audio degradation. If you suspect there are problems with your inbound audio, listening to both the decoded and loaded utterances is a very good first step to identifying and fixing these problems.
The streamed audio option is also very useful in identifying problems related to barge-in and end-of-speech detection. Often when there are problems with barge-in, the Speech Engine never gets sent audio for a decode since recognition does not take place until after barge-in has been triggered.
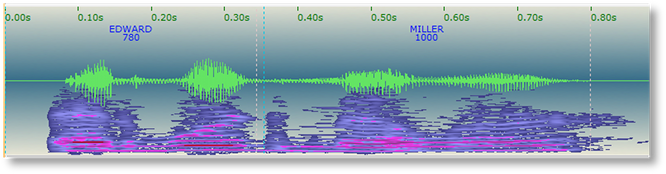
Right-clicking on the audio control graphic brings up a context menu with the following options:
Spectrogram and Waveform
Audio visualization with show both spectrogram and waveform overlays, as shown above.
Spectrogram Only
Audio visualization will only show the spectrogram related to the selected audio.
Waveform Only
Audio visualization will only show the waveform related to the selected audio (the bright green portion).
Save Audio to File...
Allows you to save the audio from the selected interaction(s) to file(s).
Callsre Audio Source
An additional drop-down control allow you to select between two different sources of audio.
- Callsre Audio Source: Input
- Callsre Audio Source: Output
In order to understand the differences between these two options, you should consider which callsre files the Speech Tuner has access to.
Typically when you load data into the Speech Tuner, you are loading it from previously collected Response Files, otherwise known as Callsre Files. The Speech Tuner regards these as Input files, since these were presented as part of a dataset to consider and analyze.
Using the Speech Tuner's Tester View, you also have the option of running decodes directly from within the Speech Tuner environment. Since these decodes are processed by the ASR, they too can have associated Callsre files, which the Speech Tuner refers to as Output files.
Now that we've described the difference between these two sources of callsre files, the option of which to select should be clearer:
- Callsre Audio Source: Input - Audio from a Callsre file loaded into the Speech Tuner (typically from one the File Open menu options)
- Callsre Audio Source: Output - Audio from a Callsre file that the Speech Tuner itself generated while performing decodes in the Tester View.
These two sources can be difference, since the tuner has the ability to modify the way in which a decode is performed in a number of ways, not least of which may be changing the grammar used to perform the decode, and as such you may want to see the before and after results of tuning in this way.


