Added in 19.2.100
LumenVox Dialect-Independent Transcription ASR is a name applied to our next generation, end-to-end deep neural network speech recognition engine that provides Natural Language Processing of speech to provide a transcript representing speech from an audio utterance.
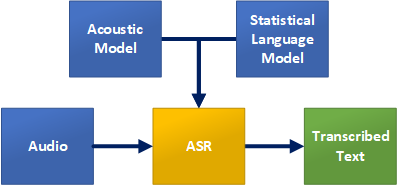
LumenVox Transcription ASR is very useful for situations where you do not want to be constrained by a specific grammar, or challenged by implementing a more complex and costly Statistical Language Model. The LumenVox Transcription ASR functionality allows you to simply provide audio and get a text representation from what was spoken using a built-in general Statistical Language Model that we've tuned for everyday use.
In addition, we've designed this functionality to be extremely easily implemented by users familiar with regular grammar-based applications. Indeed most users should be able to use this new capability with minimal application changes needed.
Regular grammars are specified containing the words and phrases you would typically expect users to say, and the ASR uses these grammars to constrain or limit the results being returned to be something within that list (even if it's not a perfect match). Using Short-Utterance Transcription to provide more Natural Language types of results, there is no grammar, but rather a highly trained statistical model for the selected language. This statistical model is used to guide the ASR based on most likely groups of words commonly used together, much like how an Internet search engine predicts what you are searching for, then prioritizes the results based on statistical likelihood of a match.
In a Natural Language application, you would no longer specify a number of responses that you expect users to say; the statistical model instead allows a more open-ended set of potential responses, which should closely represent what someone said. This approach is often used in many applications where users are free to say a wide range of potential responses. The application needs to work a little harder to determine the intent from those phrases, but it does allow users much more flexibility in what they can say. This is something that more users are coming to expect these days.
Licensing
Our LumenVox Transcription ASR functionality is accessible using our Tier 4 licenses. This Tier includes all of the functionality of Tier 3 (unlimited vocabulary grammars) and lower licenses as well as Short-Utterance Transcription.
Please talk to your Account Manager about obtaining Tier 4 licenses, and remember that these are language-specific, so if you will be working with multiple languages, you will need licenses to cover these too.
Installation
This Natural Language functionality is language-specific, but dialect independent. You need to install on each ASR server, the appropriate RPM for the language pack desired see here. You will also need appropriate licensing as described above.
Note: 64-bit Linux Only
LumenVox Natural Language functionality provided by this LumenVox Transcription ASR is only available for use with Red Hat 7 or CentOS 7, 64-bit Operating Systems. It does not run on any other Operating Systems, so you should plan your hardware accordingly.
How To
In order to make the adoption of LumenVox Transcription ASR as easy as possible for users, we have created a method of triggering this capability using a simple grammar, similar to what most users are already familiar with, so there is no learning curve needed in order to enable this technology.
The example grammar shown here is an example of how to trigger LumenVox Transcription ASR for American English (en-US):
<?
xml version='1.0'?>
<!--
This is a dummy grammar that should not be used for speech recognition.
This should only be used to switch LumenVox licensing to "SLM" mode.
-->
<grammar
xml:lang="
en-US" version="1.0" root="root" mode="voice"
xmlns="
http://www.w3.org/2001/06/grammar"
tag-format="semantics/1.0">
<meta name="TRANSCRIPTION_ENGINE" content="V2"/> <rule id="root" scope="public">
<ruleref special="NULL"/>
</rule>
</grammar>
The important aspects of this special grammar file are the language specifier ("en-US" in this example), which tells the ASR which acoustic model and statistical language models to use during transcription. There is a special "meta" tag in the grammar with a "name" parameter of value "TRANSCRIPTION_ENGINE" and a "content" parameter of value "V2". This is simply a way to tell the ASR to switch into SLM (Statistical Language Model) mode to perform transcription. "V1" can be used to activate the previous generation ASR transcription engine if needed. see here
When specifying the language, the dialect part of the language code is generally ignored, as a single acoustic and language model can handle multiple dialects. So, for example, specifying "en-US", "en-GB" or "en-AU" are all functionally equivalent. As further example, transcribing audio of a British speaker while specifying the "en-US" language will not adversely effect the transcription quality.
The special NULL rule is present just to ensure the overall grammar is compliant. This rule is not actually used for anything else. These grammars can be referenced and stored similar to any other grammar, and either referred to directly from the file system, or preferably using HTTP or HTTPS URLs.
You should create a grammar similar to this one, specifying the language you wish to use (assuming it's installed and licensed), and then you can simply send audio in using regular methods, either using the direct C/C++ API methods, or even using MRCP (v1 or v2) via the LumenVox Media Server. The maximum amount of audio that can be processed for short-utterance transcriptions provided by LumenVox Transcription ASR is around 30 minutes.
In response to sending audio and a recognition request using something like the above grammar, you will see a result resembling what was spoken.
SimpleASRClient.exe my_label my_slm_grammar.
grxml 1 300_dollars.ulaw
NBest Alternative : 1
Interpretation 1 of 1
Grammar Label : my_label
Input Sentence : THREE HUNDRED DOLLARS
Interpretation String: THREE HUNDRED DOLLARS
Interpretation Score : 999
In this example, the audio contained the phrase "300 Dollars" and the resulting Input Sentence as well as the Semantic Interpretation was "THREE HUNDRED DOLLARS", with a confidence score of 999 (very high confidence)
Running a similar example using the Media Server (MRCP) with the grammar hosted on an HTTP server:
SimpleMRCPClient.exe -grammar
http://gram-svr/my_slm_grammar.
grxml -audio 300_dollars.ulaw -v2
Processing
ASR decode request with timeout of 30 seconds
Using audio file: 300_dollars.ulaw
Connected to server. Sending RECOGNIZE request...
********************************************************************
Input Sentence : THREE HUNDRED DOLLARS
Interpretation String: THREE HUNDRED DOLLARS
Interpretation Score : 990
********************************************************************
The NLSML results from the Media Server for this operation look like this:
<?
xml version='1.0' encoding='ISO-8859-1' ?>
<result>
<interpretation grammar="
http://gram-svr/my_slm_grammar.
grxml" confidence="0.99">
<input mode="speech">THREE HUNDRED DOLLARS</input>
<instance>THREE HUNDRED DOLLARS</instance>
</interpretation>
</result>
As you can see, implementing LumenVox Transcription ASR is very easy. Also, since Tier 4 licenses have all of the same functionality contained in lower Tier licenses, you can mix regular grammar-based decodes with LumenVox Transcription ASR within your application as needed, simply by specifying the grammar you wish to use - either a regular SRGS grammar containing phrases, as is commonly done, or specifying a special grammar as described above that triggers LumenVox Transcription ASR functionality. The choice is yours.
Common Phrases and Words
Our standard Statistical Language Model that ships with this solution is designed for general purpose use as well as ease of use for our customers. As such, common words and phrases and their statistical likelihood in regular use are used. Uncommon words, such as people and place names, or product names may not be as well represented in the model (as in regular conversational occurrence), so may require special handling. Typically if a word or phrase is spoken that is not represented, the model is so rich and diverse that something very similar sounding would be returned instead (something like "Spy Cam" instead of "Zicam" for instance). Simple application logic could be used to handle this if necessary.
Programmatic Interpretation
One of the biggest challenges facing application developers working with Natural Language is how to write applications to decide what to do when presented with a string of words that come from these Natural Language responses. Think of it in terms of number of options the user could say - if there are a million possible things a user might say in response to a prompt, your application will need to handle all of these million responses somehow.
Typically, a pragmatic approach is used, where certain words or phrases are detected in the response, triggering predefined behavior, or the text returned from the transcription is processed by a Natural Language Understanding algorithm to derive meaning from what was said. Often these NLU systems are paired in multi-modal configurations with chatbots, interactive agents or website user interaction interfaces, so similar meaning can be derived from spoken or written responses from users and handled in a uniform way.
Such processing is beyond the scope of what LumenVox offers currently, so this application development is left to developers to decide how they would like to process results from these types of interactions.
Partial Results
When using the MRCP protocol to interact with the engine, it is possible to get partial results without stopping the ongoing audio stream. Adding the meta tag <meta name="PARTIAL_RESULTS" content="true"/> will trigger the engine to immediately return the transcription for the audio it has currently processed, but will continue processing streamed audio. Subsequently sending a MRCP RECOGNIZE with a grammar that does not contain his meta tag, will inform the engine to return the final complete transcription, and stop further processing. Since you need to set the PARTIAL_RESULTS meta tag for all but the last interaction, the first time you do a recognition, you will likely get an empty result. You can use the new MRCP vendor parameter delay-partial-decode to inform the engine to wait a specified number of milliseconds after receiving the partial results grammar, before returning the results.


