Starting with version 19.1, we are recommending new grammars for use with Answering Machine Detection (AMD) and Call Progress Analysis (CPA) which coincide with various enhancements and other changes that have been made to the product.
Also starting with version 19.1, we recommend all CPA and AMD applications use grammars to control aspects of configuration for this functionality. The previous configuration by settings, API or MRCP values may still be used, however any settings present in the grammar files used will override those other settings. It is for this reason that we now recommend that all users adopt the grammar-based approach when applying CPA and AMD settings for their applications.
This article describes these grammars, their settings, and how they compare to the previous grammars and settings that we have provided and documented in previous releases.
GrXML Grammar Format
Grammar files used in CPA and AMD conform to the Speech Recognition Grammar Specification (SRGS), which we describe in more technical detail in our SRGS Introduction articles.
We are using the XML variant of the grammars here, although the ABNF variant could also be used (we recommend using the GrXML variant for ease of use and to better match the documentation and examples provided).
Within the grammar, there are various lines and XML elements. Some of these are <meta> elements that contain metadata, which in this context are settings that are applied to CPA and AMD during processing. An example of this is shown here:
<meta name="STREAM|DETECTION_MODE" content="CPA"/>
In this example, the name of the setting is "STREAM|DETECTION_MODE" which determines whether the processing or detection mode is CPA or AMD. The value of the setting can be seen in the content parameter (shown as CPA here).
All CPA and AMD settings can and should be applied using these grammar meta tags. Details of each of these settings is described within this article, and supersedes previous recommendations.
Note:
Users operating versions of LumenVox prior to 19.1 can still use the settings described here, with the exception of the newly introduced CPA_MAX_TIME_FROM_CONNECT. Previously running applications should also be able to upgrade to the latest version without diminished functionality using the same settings and methods they are currently using, but we recommend all users adopt this method of applying settings via grammar metadata.
Common Settings
There are several settings common to both CPA and AMD detection modes, which are described here. These all affect audio streaming functionality, so have the STREAM| prefix in their setting names.
BARGE_IN_TIMEOUT
For AMD (Tone Detection), this value should be used to specify to the maximum amount of time that the detection mode should remain active (listening for tones) before timing out. Depending on the type of tone you are trying to detect, this may be at the beginning of the call (Busy, FAX, or SIT type tones) or later in the call if you are trying to detect a voicemail or answering machine beep. You should therefore decide within your application how long the tone detection mode should remain active, and apply that to this setting, meaning the value of this setting is implementation dependent.
<meta name="STREAM|BARGE_IN_TIMEOUT" content="30000"/>
For CPA, prior to version 19.1, it was possible for this setting to influence the behavior of CPA, returning with a BARGE_IN_TIMEOUT if this was reached before any of the CPA classifications are reached. In reality, when working with CPA, you want one of the possible CPA classifications to be returned, rather than BARGE_IN_TIMEOUT, so in version 19.1 onward, this BARGE_IN_TIMEOUT setting is forced to a value of 10,000 ms greater than any of the CPA settings, so as not to interfere with the algorithm, and therefore guarantee one of the CPA classifications be returned. We therefore recommend AMD and CPA users upgrade to version 19.1 or later at their earliest convenience. Setting this value in CPA mode has no effect in the latest versions
END_OF_SPEECH_TIMEOUT
This is the amount of time, after someone has started speaking, before the algorithm times out (and assumes there is too much speech). This setting is to prevent someone from continually speaking and preventing the application from continuing. You could also consider this setting to be the maximum amount of human speech to consider.
<meta name="STREAM|END_OF_SPEECH_TIMEOUT" content="30000"/>
For AMD, this setting has no real effect, since the tone detection algorithm is not looking for human speech (in fact it performs various complex measures to ignore it), so this setting should be set to some value high enough to be ignored. Equal to, or higher than BARGE_IN_TIMEOUT would normally be appropriate. Again, for AMD, setting this value to a low number should have no effect on the algorithm.
For CPA in versions prior to 19.1, applying a value to this setting that was lower than the limit of the CPA settings could inadvertently affect the algorithm and cause unexpected results. We therefore recommend all CPA users working with versions prior to LumenVox 19.1 set this value to something greater than the largest CPA setting value in order to avoid unexpected behavior. In version 19.1, this value is internally forced to be 10,000 ms greater than the largest CPA value when operating in this mode, so users can largely ignore this setting.
VAD_EOS_DELAY
When working with CPA (detecting the amount of human speech present in a greeting), this setting defines how much silence after someone stops talking is
allowed before triggering an end-of-speech event, which in turn
generates a CPA result. Having some amount of silence after someone stops
talking is necessary to allow for the natural gaps and pauses between
words or sentences.
Not allowing enough time for these silence gaps can
lead to premature triggering of the end-of-speech event. The duration of
speech between start-of-speech and end-of-speech is critical to
determining how much human speech there actually was, and this is used
to determine whether there was a short utterance (Residence), a medium
utterance (Business) or a lengthier utterance (Unknown Speech or Machine
message).
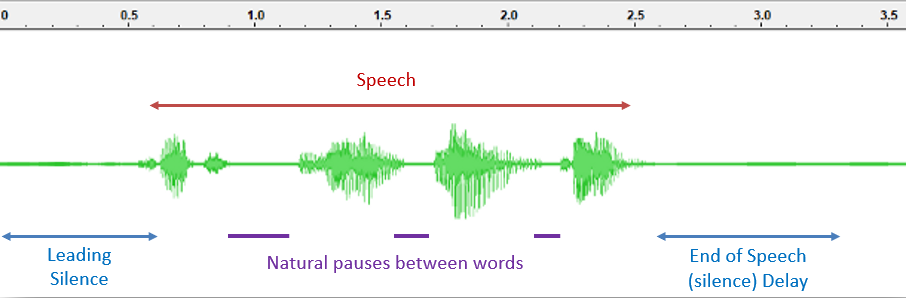
As can be seen in this diagram, the purple periods of silence are
normal and expected within natural speech. The End of Speech (Silence)
Delay (VAD_EOS_DELAY) is used to check whether silence is one of these
gaps between words, or if the person has finished speaking, at which
point a result can be generated.
Specifying too much of a
delay here to accommodate longer silence "gaps" helps the CPA algorithm a
lot, since it can better categorize the length of utterance, however
this comes at the cost of more of a delay for the human that answered
the call.
The default value for this setting is 0.8 seconds (800 ms) for Tone Detection/AMD (the same as for ASR) and a slightly longer 1.2 seconds (1200ms) for Human Speech Detection/CPA
To specify the default 1200ms (1.2 seconds) of VAD_EOS_DELAY, add the following to your CPA grammar.
<meta name="STREAM|VAD_EOS_DELAY" content="1200"/>
We have found that this value works well for most situations, so we
recommend using this if you are unsure of which value to use when working with CPA.
This default value (1200ms) will automatically be used in CPA if the above setting is not explicitly specified.
For advanced CPA users, or those more sensitive to machine-to-human
misclassifications, such as call centers, changing this to some higher
value of 1500ms, for example, can yield significantly better CPA
accuracy, at the expense of an additional delay observed by the person
answering the call. The difference in this example (default 1200ms to
higher value of 1500ms) would be 300ms of additional delay, or a total
of 1500ms (1.5 seconds) before being routed to an agent or getting some
other response from the system.
Application developers should
consider how much delay should be acceptable for humans being called by
their applications, noting that machines don't care about these delays.
There is a balance and trade-off between CPA accuracy and this delay.
For AMD, this setting is not really used, since it relates to human speech detection, which does not apply to tone detection. The default value (800 ms) is usually sufficient.
Tip:
When working with CPA interactions, if you are working with short utterances, some applications might not wish to use the full Human (residential or business) versus Machine predictive classification, preferring instead to simply determine whether human speech is present (resulting in UNKNOWN SPEECH), or no human speech (resulting in UNKNOWN SILENCE). If this is the case, you could reduce the VAD_EOS_DELAY setting to some minimal value (perhaps 100-400ms) to get faster responses.
VAD_STREAM_INIT_DELAY
This setting is used internally by the Voice Activity Detection mechanism to determine the amount of background noise present in the audio by performing a deep acoustic analysis of the first portion of the audio stream.
<meta name="STREAM|VAD_STREAM_INIT_DELAY" content="0"/>
Typically, the default value of 100 ms for AMD or ASR (0 for CPA implementations) should not be changed, however for advanced users,
or those with unusual acoustic requirements, this value can be adjusted to
accommodate the specific working environment. See our client_property.conf article for more details.
Changes in 19.1 for CPA
Starting with version 19.1 of LumenVox, the VAD_STREAM_INIT_DELAY setting is automatically configured to use the optimal value of 0, so no longer needs to be specified by any settings. Users with older versions should be sure to set this optimal value (0) when working with CPA interactions.
Call Progress Analysis
As is described in other articles in this section, Call Progress Analysis focuses on identifying whether there is a human answering the call, as opposed to a machine answering the call. There may also be further classification to determine whether the human is answering as a business, or as a residence.
HUMAN RESIDENCE TIME
The classification between HUMAN RESIDENCE and HUMAN BUSINESS is determined by the length of time the person answering the call speaks for. We determined using lots of statistical data that residential calls are typically answered with speech that is shorter than 1.8 seconds (1800 ms) and businesses answer with greetings typically longer than this. For example
- "Hello" or "Hello this is John" - typically short utterances for RESIDENTIAL numbers
- "Hello this is LumenVox, how may I direct your call today?" - typically longer utterances for BUSINESS numbers
The settings for determining this classification between these two is the CPA_HUMAN_RESIDENCE_TIME, which has a default value of 1800 ms, so any utterance shorter than this is typically classified HUMAN RESIDENCE and anything longer is typically HUMAN BUSINESS. In the grammar, this setting appears as shown here:
<meta name="STREAM|CPA_HUMAN_RESIDENCE_TIME" content="1800"/>
Tip
If your application only wishes to return UNKNOWN SPEECH when human speech is detected, or UNKNOWN SILENCE when there is none, set both CPA_HUMAN_RESIDENCE_TIME and CPA_HUMAN_BUSINESS_TIME to the same low value (10 is a suitable value for this). This is not a typical configuration.
HUMAN BUSINESS TIME
Human speech that lasts for more than CPA_HUMAN_RESIDENCE_TIME and less than CPA_HUMAN_BUSINESS_TIME is classified and returned as HUMAN BUSINESS
If speech is detected that lasts for more than is typical for a human business greeting of 3 seconds (3000 ms), this is classified and returned as UNKNOWN SPEECH. The setting that controls this is the CPA_HUMAN_BUSINESS_TIME as shown below. We recommend using the default value for this unless you have a good reason to change it:
<meta name="STREAM|CPA_HUMAN_BUSINESS_TIME" content="3000"/>
UNKNOWN SPEECH results returned from speech lasting greater than CPA_HUMAN_BUSINESS_TIME (default 3 seconds) in this way are often the result of an answering machine or perhaps a pre-recorded message, which tend to have longer utterances.
Note that setting CPA_HUMAN_BUSINESS_TIME to the same value as CPA_HUMAN_RESIDENCE_TIME will effectively disable the option of returning any HUMAN BUSINESS results, since any speech lower than CPA_HUMAN_RESIDENCE_TIME would be returned as HUMAN RESIDENCE and anything greater would be returned as UNKNOWN SPEECH.
Setting both to a very small value (say 10 ms for instance) will force only UNKNOWN SPEECH or UNKNOWN SILENCE to be returned. This configuration may be useful, if your application only wishes to detect whether human speech is detected or not (not commonly used).
UNKNOWN SILENCE
Whenever CPA detection is enabled, human speech is generally expected, either by the person answering the call, or a recorded message, possibly generated by a system error or an answering machine. There is, however, another possibility, which is silence, where no human speech is detected at all.
This may be silence before someone starts speaking, or silence because no speech is present. Either way, there needs to be a way to limit the amount of time that the algorithm waits to see if any speech is present before timing out. This is the CPA_UNKNOWN_SILENCE_TIMEOUT period, which defaults to 5 seconds (5000 ms) and is controlled as shown below:
<meta name="STREAM|CPA_UNKNOWN_SILENCE_TIMEOUT" content="5000"/>
If no speech is detected before this timeout is reached, the UNKNOWN SILENCE classification will be made and returned, allowing the application to decide how to proceed (perhaps prompting to determine if a human is present, or hanging up for example)
CPA_MAX_TIME_FROM_CONNECT
This new setting was introduced in version 19.1 and allows users to conveniently apply a single setting to auto-scale the three settings above (CPA_HUMAN_RESIDENCE_TIME, CPA_HUMAN_BUSINESS_TIME and CPA_UNKNOWN_SILENCE_TIMEOUT), based on the desired maximum amount of time before a result is returned to the application.
<meta name="STREAM|CPA_MAX_TIME_FROM_CONNECT" content="5000"/>
This setting, when used, overrides the other three settings, and a predefined set of rules internally auto-scales those settings to accommodate a result within the desired time frame, making the best possible classification it can. See our CPA_MAX_TIME_FROM_CONNECT - 19.1.100 documentation for more detailed information about how to use this new setting.
Note that when this setting is used, the "Common Settings" described above, with the exception of VAD_EOS_DELAY, are also overridden with internally scaled values (in other words, this is the only setting that needs to be specified when it is used).
Tone Detection
When working with tone detection, the above CPA settings do not apply. Instead, a different set of options is used to customize Tone Detection behavior as described in this section. Note that the "Common Settings" described above also apply to Tone Detection.
<meta name="STREAM|DETECTION_MODE" content="Tone"/>
The above metatag should be used when Tone Detection should be enabled. Specifically the content should be set to "Tone" to enable Tone Detection (as opposed to "CPA")
The following 4 configuration settings are used to selectively enable different types of Tone Detection results
AMD_CUSTOM_ENABLE
When Answering Machine Detection (AMD) is required, this configuration should be set to a value of true in the metatag content, as shown here:
<meta name="AMD_CUSTOM_ENABLE" content="true"/>
This enables the Answering Machine Detection portion of the algorithm. When this is "true", any tone in the audio stream that appears to be from an answering machine will be returned as a result (typically with the "BEEP" designation for INPUT TEXT and Semantic Interpretation - see below for details)
When this is assigned a content value of "false", the Answering Machine Detection functionality will be disabled and the "BEEP" result will not be returned, with such tones being ignored.
FAX_CUSTOM_ENABLE
When detection of Fax Tones is required, this
configuration should be set to a value of true in the metatag content,
as shown here:
<meta name="FAX_CUSTOM_ENABLE" content="true"/>
This enables the Fax Tone Detection portion of the algorithm. When this is "true", tones in the audio stream detected to be from a Fax Machine will be returned as a result (typically with the "FAX" designation for INPUT TEXT and Semantic Interpretation - see below for details)
When this is assigned a content value of "false", the Fax machine detection functionality will be disabled and the "FAX" result will not be returned, with such tones being ignored.
SIT_CUSTOM_ENABLE
Special Information Tones (SIT) are generated by telephony systems and networks to indicate certain situations, such as when a call cannot be completed as dialed. These appear as a series of three rising tones, generally followed by an informational message that describes the issue. When detection of these Special Information Tones is required, this
configuration should be set to a value of "true" in the metatag content,
as shown here:
<meta name="SIT_CUSTOM_ENABLE" content="true"/>
Once SIT detection is enabled, the portion of the algorithm that processes these tones becomes active and will automatically detect one of these tones, when present:
- SIT REORDER LOCAL
- SIT VACANT CODE
- SIT NO CIRCUIT LOCAL
- SIT INTERCEPT
- SIT REORDER DISTANT
- SIT NO CIRCUIT DISTANT
- SIT OTHER
The specific meaning behind each of these, and the interpretation of these responses is standardized by the International Telecommunication Union (ITU) and described in various references, such as this Wikipedia reference on Special Information Tones.
For each of these tones, CPA will generate the appropriate INPUT TEXT as well as Semantic Information (SI) response in the returned result. The "INPUT TEXT" and "Semantic Interpretation" values returned in such results can also be customized as needed by the application using different settings within the AMD grammar being used.
To modify the INPUT TEXT for a specific SIT response, the following settings can be modified. Shown here are the recommended default values within the AMD grammar:
<meta name="SIT_REORDER_LOCAL_CUSTOM_INPUT_TEXT" content="SIT REORDER LOCAL"/>
<meta name="SIT_VACANT_CODE_CUSTOM_INPUT_TEXT" content="SIT VACANT CODE"/>
<meta name="SIT_NO_CIRCUIT_LOCAL_CUSTOM_INPUT_TEXT" content="SIT NO CIRCUIT LOCAL"/>
<meta name="SIT_INTERCEPT_CUSTOM_INPUT_TEXT" content="SIT INTERCEPT"/>
<meta name="SIT_REORDER_DISTANT_CUSTOM_INPUT_TEXT" content="SIT REORDER DISTANT"/>
<meta name="SIT_NO_CIRCUIT_DISTANT_CUSTOM_INPUT_TEXT" content="SIT NO CIRCUIT DISTANT"/>
<meta name="SIT_OTHER_CUSTOM_INPUT_TEXT" content="SIT OTHER"/>
Each entry corresponds with the matching Special Information Tone listed above.
For example, if you wanted to change the INPUT TEXT associated with "SIT VACANT CODE" to be some other string, such as "VACANT", you can simply change the string value in the content parameter relating to the metatag with the name "SIT_VACANT_CODE_CUSTOM_INPUT_TEXT".
Similarly, if the desired Semantic Interpretation string needs to be modified for an application for some reason, the section of the grammar towards the bottom matches the "INPUT TEXT" (described above) to the corresponding SI string that will be returned.
<rule id="root" scope="public">
<one-of>
<item>BEEP<tag>out="BEEP"</tag></item>
<item>FAX<tag>out="FAX"</tag></item>
<item>BUSY<tag>out="BUSY"</tag></item>
<item>SPEECH<tag>out="SPEECH"</tag></item>
<item>SIT REORDER LOCAL<tag>out="SIT"</tag></item>
<item>SIT VACANT CODE<tag>out="SIT"</tag></item>
<item>SIT NO CIRCUIT LOCAL<tag>out="SIT"</tag></item>
<item>SIT INTERCEPT<tag>out="SIT"</tag></item>
<item>SIT REORDER DISTANT<tag>out="SIT"</tag></item>
<item>SIT NO CIRCUIT DISTANT<tag>out="SIT"</tag></item>
<item>SIT OTHER<tag>out="SIT"</tag></item>
</one-of>
</rule>
By way of example, if we had changed the INPUT TEXT of the SIT VACANT CODE to "VACANT" as described above, the <item> element shown here would need to be modified to match the INPUT TEXT being used, so in this example, it would become:
<item>VACANT<tag>out="SIT"</tag></item>
You can see this modified / customized INPUT TEXT highlighted in red. Again, by way of example, if you wanted to change the Semantic Interpretation returned from a match of this type to "MY SIT SI STRING", you should change the value of the out variable within the <tag> element as shown in red here:
<item>VACANT<tag>out="MY SIT SI STRING"</tag></item>
The values used for both INPUT TEXT and SI within the grammar (and therefore returned to your application) are implementation specific to your needs, however we recommend using the default values unless you have a strong reason to change these.
Note that all SIT results are designed to return a common "SIT" Semantic Interpretation string, regardless of the type of SIT tone detected. This can be useful within applications if you only care that there was a SIT tone present, but not really caring about which type of SIT tone it was (which is rarely needed in speech applications).
See the sections lower down this article for more information about customizing and using INPUT TEXT and Semantic Interpretation values in results.
BUSY_CUSTOM_ENABLE
When BUSY tone detection is required, this
configuration should be set to a value of "true" in the metatag content,
as shown here:
<meta name="BUSY_CUSTOM_ENABLE" content="true"/>
This enables the Busy tone detection portion of the algorithm. When this is "true", if a Busy tone in the first 7.5 seconds (7500 ms) of the audio stream is detected, a busy signal will be returned as a result (typically with the "BUSY" designation for INPUT TEXT and Semantic Interpretation - see below for details)
When this is assigned the default content value of "false", the Busy tone detection functionality will be disabled and the "BUSY" result will not be returned, with such tones being ignored.
NOTE:
This BUSY tone detection algorithm was introduced in LumenVox 19.1, so you should upgrade to the latest version in order to utilize this capability. In order to maintain backward compatibility with existing applications, the default setting for this detection algorithm if False (disabled).
BUSY tones are only detected within the first 7.5 seconds (7500 ms) of the audio stream from a call. Also, many applications only receive the audio stream *after* the call has connected, so ring tones, busy tones and so on are not present within the audio stream, which means that depending upon your system configuration, you may not be able to detect busy tones, or may need to change platform settings in order to access pre-connection audio in order to detect them if needed.
Customizing INPUT TEXT in results
As described in the Speech Recognition Grammar Specification, INPUT TEXT (sometimes referred to as Raw Text or Literal Text) is returned as part of a response from the system. This INPUT TEXT is a string representation of what was detected, and in the case of CPA and AMD, may be one of the following default values:
- BEEP (when AMD_CUSTOM_ENABLED is "true" and an answering machine tone is detected)
- FAX (when FAX_CUSTOM_ENABLED is "true" and a fax tone is detected)
- BUSY (when BUSY_CUSTOM_ENABLED is "true" and a busy tone is detected)
There are also several similar responses relating to SIT tones as described earlier in this article.
To modify the INPUT TEXT returned from one of these cases, you should modify the corresponding setting in the grammar as shown below and highlighted in red:
<meta name="AMD_CUSTOM_INPUT_TEXT" content="BEEP"/>
<meta name="FAX_CUSTOM_INPUT_TEXT" content="FAX"/>
<meta name="BUSY_CUSTOM_INPUT_TEXT" content="BUSY"/>
Changing the strings shown here in red will result in a custom INPUT TEXT string being returned in your result from a matching detection.
Important:
If you change the value of your INPUT TEXT for a certain detection type, you must also update the corresponding <item> element entry in the grammar, since this is used to match the INPUT TEXT when generating the Semantic Interpretation result (described in the section below).
Customizing Semantic Interpretation in results
Similar to creating custom INPUT TEXT strings in the results generated by various CPA and AMD responses, the Semantic Interpretation string, as defined by the Semantic Interpretation for Speech Recognition (SISR) specification, which usually represents the meaning or fundamental intent of the result can also be customized by modifying the out rule variable of the <tag> elements of the corresponding entries in the grammar, as highlighted in red below:
<rule id="root" scope="public">
<one-of>
<item>BEEP<tag>out="BEEP"</tag></item>
<item>FAX<tag>out="FAX"</tag></item>
<item>BUSY<tag>out="BUSY"</tag></item>
<item>SIT REORDER LOCAL<tag>out="SIT"</tag></item>
<item>SIT VACANT CODE<tag>out="SIT"</tag></item>
<item>SIT NO CIRCUIT LOCAL<tag>out="SIT"</tag></item>
<item>SIT INTERCEPT<tag>out="SIT"</tag></item>
<item>SIT REORDER DISTANT<tag>out="SIT"</tag></item>
<item>SIT NO CIRCUIT DISTANT<tag>out="SIT"</tag></item>
<item>SIT OTHER<tag>out="SIT"</tag></item>
</one-of>
</rule>
While it is possible to change the values of these strings, we recommend using the defaults unless you have a compelling reason to use something else, for example to accommodate some specific requirement of your application.
Recommended Grammars
CPA / AMD Builtin Grammars Deprecated
As
mentioned above, we have deprecated support for builtin CPA and AMD
grammars, in favor of updated grammars which add more functionality and
are clearer and easier to use. The special builtin grammars for CPA and
AMD will continue to work for backward compatibility only. All users are
encouraged to use the new grammars described in the Grammars in CPA and AMD article.
Below you will see links to download the grammars we recommend using with AMD and CPA requests, which you can further customize using the settings described above as needed.
|
Grammar File Name |
Comments |
|
CallProgressAnalysis.grxml |
Simple CPA grammar not using CPA_MAX_TIME_FROM_CONNECT option |
|
CallProgressAnalysis_max5000.grxml |
CPA_MAX_TIME_FROM_CONNECT specified to return CPA result within 5000ms |
|
ToneDetection.grxml |
Simple AMD grammar without BUSY tone detection enabled |
|
ToneDetection_busy.grxml |
AMD grammar with BUSY tone detection enabled |
It is important to reiterate that these grammars represent the latest recommended method of applying settings when working with CPA or AMD functionality. Previous methods of applying settings via configuration or API calls can still be used, however that use should be viewed as either deprecated or for advanced use only. All users and applications should adopt and use these new grammars, making custom modifications where needed.



