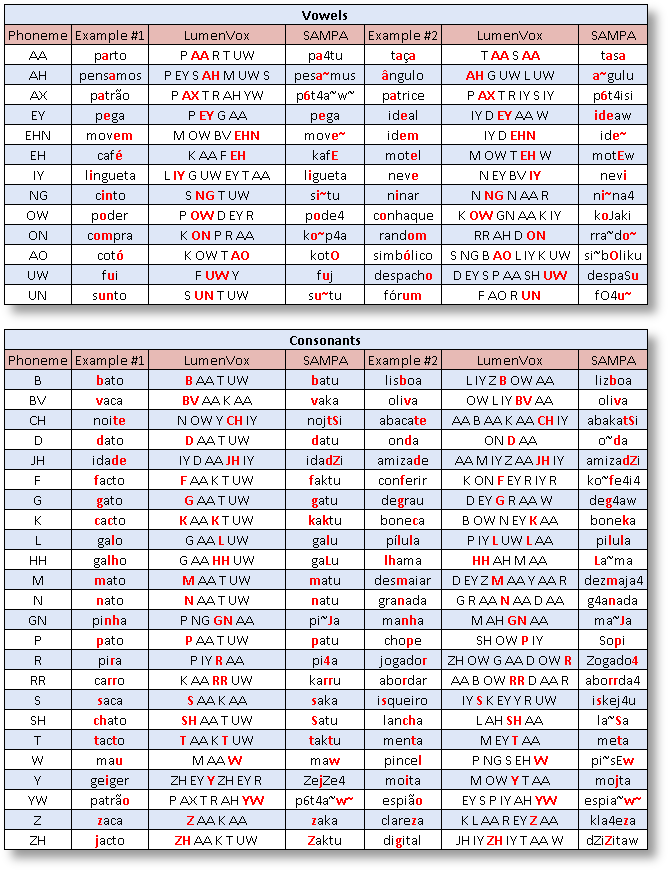
The unit of sound the recognition engine actually recognizes are phonemes. All phrase formats are ultimately translated into phonetic spelling for decoding. These phonetic spellings can be directly entered if surrounded by curly braces when using inline phonetic format. See Using Phonetic Spellings and Adding Foreign Words for more information about working with phonemes.
The phoneme alphabet (such as AA or EH) that LumenVox implements is a modified version of the CMU Pronouncing Dictionary, which originally derived from Arpabet. Note that the specific alphabet used, as listed below, is specific to LumenVox, so care should be exercised when using CMU or ARPAbet from non-LumenVox sources.
The SAMPA representations shown alongside the LumenVox phonemes indicate the mapping used internally when working with SAMPA conversions, such as when writing or using custom lexicons to aid in the pronunciation of certain words or phrases. Note that this mapping and the phonemes used are specific to LumenVox, so care should be used when utilizing SAMPA or CMU phonemes from non-LumenVox sources.
Below is the Brazilian Portuguese (pt-BR) phonetic alphabet used by the ASR decoder, along with SAMPA equivalent representations: