A no-input event is what happens when the ASR is asked to perform a recognition, but no audio is detected within the timeouts specified. The typical behavior of an application when faced with a no-input event is to prompt the user ("I'm sorry, but I didn't hear what you said"). However, it always possible to get no-input events when the user actually spoke, and so part of tuning a speech application is to ensure that the voice activity detection (VAD) of the ASR is tuned appropriately for your application. The No-Input Tuning Wizard can help you visualize how the ASR is performing for no-input events.
The goal in no-input tuning is to make sure that whenever a user speaks, the ASR is recognizing that there was speech. This is called "barge-in" because it allows a user to barge-in over a playing prompt by speaking to interrupt the prompt. When barge-in does not occur, the ASR returns a no-input to the voice platform. Too many no-input events mean that users become frustrated with the application as it never seems to "hear" what they said.
Transcribing No-Input Events
To get the most out of the No-Input Tuning Wizard, you must use the Transcriber to transcribe No-Input events (note that as this is a new feature in version 12.2 of the Speech Tuner, users with older data sets may need to re-transcribe them). There are some important differences between transcribing normal speech events and no-input events:

- To store the audio for a no-input event, you must have utterance file verbosity set to 3 when they are captured.
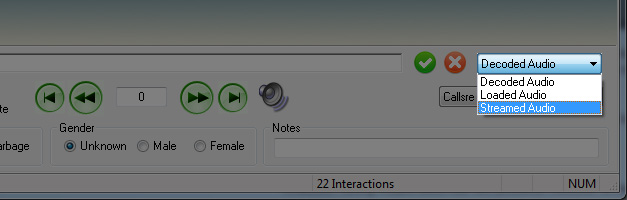
- To hear the audio in the Transcriber, you must click the Decoded Audio dropdown box and set it to Streamed Audio.
- If there is valid speech in the streamed audio, transcribe it as normal.
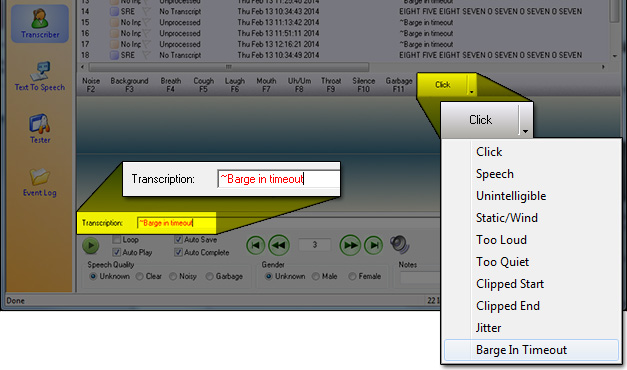
- If there is no valid speech in the streamed audio, transcribe it as ~Barge in timeout (the "Decoded Text" from the ASR for no-input events is "~Barge in timeout" so the transcript should match the Decoded Text). You can click the dropdown labeled Click in the Transcriber to access a shortcut to put this into the transcript text automatically.
Evaluating No-Input Events
Once no-input events have been transcribed, the Tuner classifies them as one of two categories:
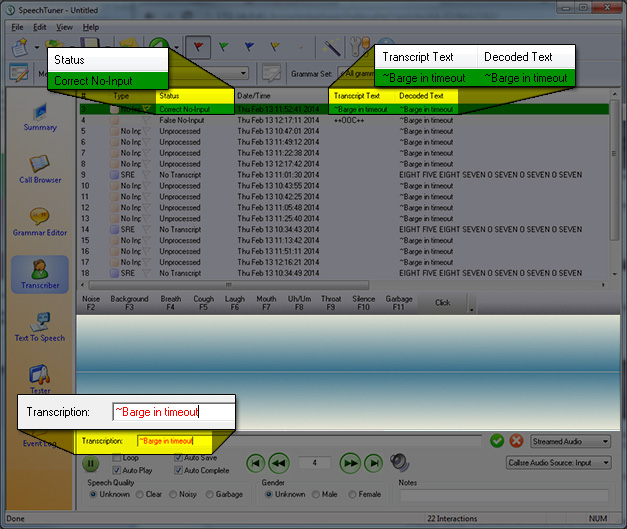
- A Correct No-Input is an event where no input was detected, and the transcript text is ~Barge in timeout. This means that there was no speech present, and so the correct result from the ASR was to return no input .
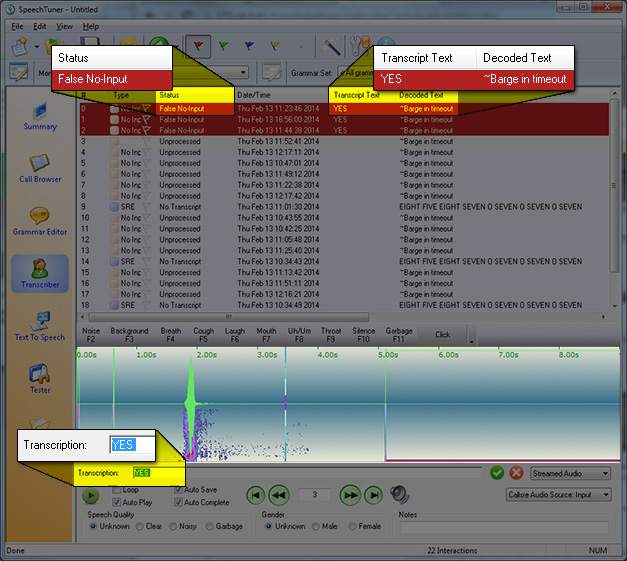
- A False No-Input is an event where no input was detected, but the transcript text is something besides ~Barge in timeout. This means that the ASR should have detected speech but did not (note that even things like OOG or OOC utterances may result in False No-Input events).
No-Input Tuning Wizard
After going through the Tuning Wizard and selecting no-input events as an issue to focus on, you will be taken to the No-Input Results page:
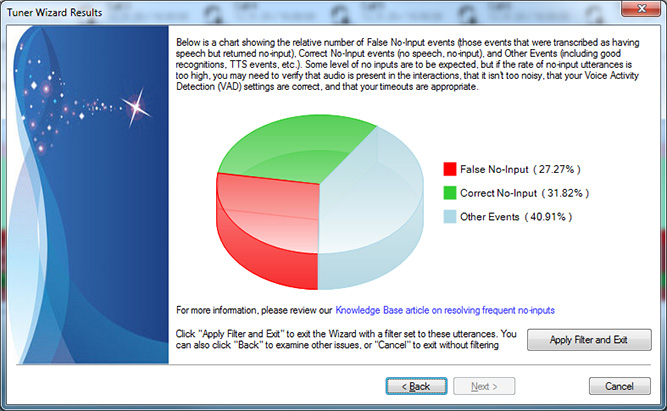
The graph breaks down the relative frequency of false no-inputs, correct no-inputs, and other events (everything else, including valid speech decodes, TTS syntheses, DTMF decodes, etc.). You can click the Apply Filter and Exit button on this page to filter your results to just no-input events in order to focus on them specifically.
Improving No-Input Performance
If you feel the frequency of false no-input events is too high, the first thing to investigate is the audio itself. Listen to the streamed audio that in the Transcriber and look at the waveform.
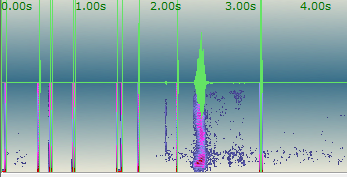
Some common issues that throw off VAD are:
- Loud noise (especially line noises, pops, clicks, etc.) in the first 100 milliseconds of audio (see the above image for an example).
- Incredibly low volume for the speaker.
- Loud, consistent background noise.
- Distorted audio that is unrecognizable.
Most chronic no-input problems are related to the voice platform itself and not the recognizer, so if your audio shows serious problems, solve those before investigating too much further. But if you still have issues, you can adjust some VAD settings in the Tuner by going to Edit > Settings and clicking the Streaming tab.
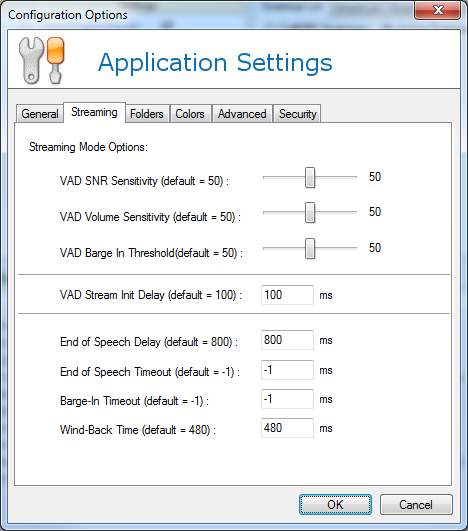
Common VAD settings to adjust are:
- VAD SNR Sensitivity controls how much louder the speaker must be than the background (lower makes barge-in easier). Useful for utterances with lots of background noise.
- VAD Volume Sensitivity is how loud the signal must be, period, to barge-in (this is the "sensitivity" setting used in VXML and MRCP). Set this down to help with quiet utterances.
- VAD Stream Init Delay is how much time, in milliseconds, the VAD will sample at the start of an audio stream to determine background noise levels. If you have audio within the first 100 ms of your stream, that can throw off the VAD algorithm, so you can disable that sampling by setting this to 0 (though you may find that you allow too many barge-in events as a result, so be careful).
- End of Speech Delay (similar to the completetimeout/incompletetimeout values in VXML and speech-complete-timeout/speech-incomplete-timeout values in MRCP) is how much time a user has to finish speaking once they've started.
- Barge-in Timeout (same as the timeout value in VXML/MRCP) is how long a user has to start speaking before no-input is returned.
Most of the other streaming settings here are rarely used and can largely be left alone. See our documentation on Sensitivity Settings in the ASR help for more information on what these settings do and how they should be used.
Running Tests in Streaming Mode
In order to test changes to VAD settings, you must put the Tuner into Streaming mode. Do this by going to Edit > Settings and clicking the General tab and changing the Decode Mode to Stream Files:
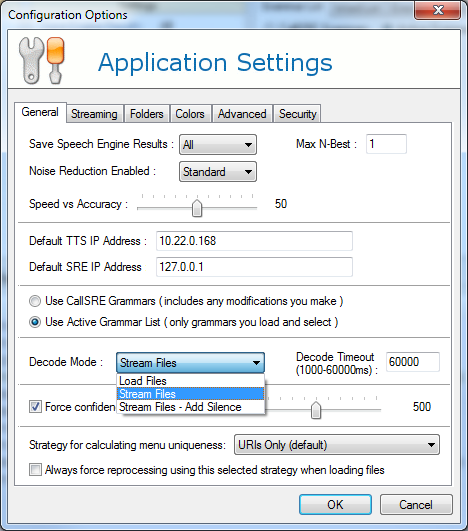
By default, Load Files is used, which does not put any audio through the VAD. Using VAD requires more processing time, so it is generally not desirable to leave the Tuner in Stream Files decode mode unless you are specifically testing VAD changes.


