The statistics area provides most of the information about accuracy and other vital clues about application performance. It is generally the first place to look when trying to understand how an application is working. Most of the statistics require transcripts before they can be generated, so it is a good idea to transcribe your data before spending much time interpreting statistics.
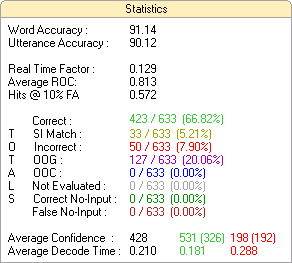
The following information is displayed in the Statistics pane:
Word Accuracy
The percentage of words that were correctly recognized by the Speech Engine.
Utterance Accuracy
The percentage of interactions in which every word was correctly recognized. Note that this statistic counts SI Matches (see below) as correct results, and does not count OOV (see below) responses as incorrect.
Elapsed time
The amount of time that has elapsed in the current test. (This will be blank if no test is running.)
Remaining
The amount of time that is remaining in the current test. (This will be blank if no test is running.)
Real Time Factor
The average amount of time it took the Engine to perform a recognition, expressed as a percentage of the total audio length. If an interaction was 2 seconds long and the Engine decoded it in 200 milliseconds, the real time factor would be 0.10 (2 seconds times 0.10 equals 200 milliseconds).
Average ROC
The average Receiver Operator Characteristic.
Hits @ 10% FA
The percentage of correct results (the hits) at a false acceptance rate of 10%. The false acceptance rate is related to the rejection threshold: it is the percentage of incorrect responses with confidence scores above the rejection threshold. What this statistic measures is the percentage of correct results if the rejection threshold is set so that the false acceptance rate is 10%.
Correct
The number of correctly recognized interactions out of the total number of interactions. The percentage is displayed in parentheses.
SI Match
The number of interactions that were not correctly recognized but which had a correct semantic interpretation (so that there would be no difference in the return if the correct result had been obtained). A common example of an SI match is if both "yes" and "yeah" have the same semantic interpretation. If the Engine recognizes "yeah" when the speaker said "yes," this is technically an incorrect result even though it had the same meaning. SI Matches are not counted as incorrect results and are counted as correct results when calculating Utterance Accuracy.
Incorrect
The number of incorrectly recognized interactions out of the total number of interactions. The percentage is displayed in parentheses.
OOV
The number of interactions that were out of vocabulary out of the total number of interactions. An OOV interaction is one in which the speaker says a word or phrase that is not represented in the active grammars, meaning there is no way the Speech Engine can return the correct result.
Not Evaluated
The number of interactions that were not evaluated for one reason or another (e.g. no transcript or some kind of other problem).
Correct No-Input
The number of "No-Input" interactions that were correctly classified as no-input (no human speech). This happens when the Voice Activity Detection in the ASR correctly determines that there was no speech present.
False No-Input
The number of "No-Input" interactions that were incorrectly classified as no-input. This happens when speech was present, but the Voice Activity Detection settings did not trigger a barge-in, which resulted in a no-input. Changing your VAD settings may help improve sensitivity to this failure if this becomes a significant problem in your environment.
Average Confidence
There are several numbers for this statistic:
- The first, in blue text, is the average confidence score for all interactions.
- The middle set of numbers, in green, is the average confidence score for correct answers. The number in parentheses is the standard deviation of confidence scores for correct answers. SI Matches are counted as correct answers for the purpose of this statistic.
- The final set of numbers, in red, is the average confidence score for incorrect answers. The number in parentheses is the standard deviation of confidence scores for incorrect answers.
Word and Error Lists
These lists display information about the individually recognized words and errors. They provide a good way to get detailed information about exactly how your users are interacting with your speech applications.
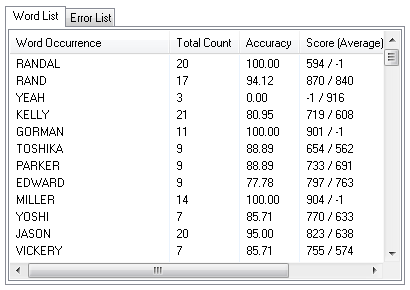
The following information is displayed in the Word and Error Lists:
Word or Error Occurrence
Each word that was recognized in the loaded and filtered dataset. Note that multi-word phrases are broken down into individual words in this list.
Total Count
The number of times the word was said within the dataset.
Accuracy
The percentage of times the word was correctly recognized.
Score (Average)
The confidence score for the word, with the average score for the word in parentheses.
Re-Evaluating Interactions
The Speech Tuner allows a wide range of options to manipulate the interactions selected at any given time, as well as the option of editing grammars, changing ASR settings and so on.
By design, the statistics relating to all currently active interactions are meant to remain in-sync with whatever changes the user makes to these various selections.
In earlier versions of the Speech Tuner, it was possible that the statistics being displayed could become slightly out-of-sync with the currently active interactions when manipulating the data in certain ways, which was undesirable.
Because of this, a seldom used, but potentially useful feature was introduced. This is the "Re-evaluate Selection" option in the right-click menu when clicking on the interaction list, which is designed to explicitly force the Speech Tuner to perform a new evaluation of the selected interactions
Normally, the Semantic Interpretations and various accuracy statistics related to all interactions are updated on the fly whenever something changes, however due to the large combination of options to filter things as well as modify grammars, ASR settings and so on, it is possible that the statistics for some of these interactions may get a little out-of-sync.
In much earlier versions of the Speech Tuner, prior to a significant redesign in 12.2.100 (September 2, 2014), this getting out-of-sync was more likely to occur that in more recent versions, so the use of this option is much less often needed these days.
This “Re-Evaluate Selection” option allows users to explicitly force a reprocessing of selected interactions and their corresponding statistics if ever there was any doubt about their correctness.
We chose to leave this in place, just in case it was ever needed again


